Building Content Silos Using the Cluster Tree Diagram
Building the cluster tree was a breakthrough in creating the query clusters. Here’s a sample of a query cluster:
are there miniature english bulldogs [0]
├── is there a miniature english bulldog [10.0]
│ ├── is there such thing as a toy bulldog [8.0]
│ ├── what is the smallest english bulldog [8.0]
│ ├── is there such thing as a teacup english bulldog
│ ├── are there toy english bulldogs [8.0]
│ ├── how do you get a mini english bulldog [8.0]
│ ├── are mini english bulldogs real [8.0]
│ │ └── is there a small version of an english bull
│ ├── how big do toy bulldogs get [8.0]
│ └── is there such thing as a miniature english bull
├── is there a mini english bulldog [9.0]
│ └── are there mini english bulldogs [10.0]
│ └── are there small english bulldogs [8.0]
├── how big do micro english bulldogs get [8.0]
│ └── how big do mini english bulldogs get [9.0]
│ └── how big do teacup bulldogs get [8.0]
│ └── how big does a micro bulldog get [8.0]
As you can see, the cluster tree makes it easy to visualize the relationship between the queries in a cluster.
However, transforming the cluster tree into a content silo with articles briefs and interlinking plan requires some manual work.
If Google’s algorithm understood the queries perfectly, you could implement the query clusters as it is. But despite the astronomical amount of data Google has, it still has many gaps in its understanding.
Therefore, you need to examine the cluster tree and make any corrections based on your knowledge of the field and the guidelines in this article.
Core Concepts
Before we go through the guidelines, we need to learn a couple of core concepts. These concepts are:
- Similarity Score
- Natural Language Processing
Let’s start with similarity score.
Similarity Score
For any parent-child pair, the similarity score is the number next to the child query. For the following parent-child pair, the similarity score is 7.
why is my bulldog so small [5.0]
└── why is my english bulldog so small [7.0]
The similarity score shows how closely the parent query resembles the child query.
In the real-world, we use faces to compare resemblance. The faces of some children resemble their parents so much that even a stranger can immediately tell that they are related.
Sometimes, the facial resemblance is apparent from a certain angle but not at all times.
Other times, only a part of the face may match – like say, the nose or the eyes.
So, the degree to which a child resembles a parent varies.
In the search-engine world, we use the SERP of the query to compare resemblance.
While the SERPs for some parent-child queries bear a strong resemblance, the SERPs for some other parent-child queries may bear a weak resemblance.
The similarity score indicates the strength of the resemblance of the SERPs of the parent and the child.
The table below shows how to interpret the similarity score:
| Similarity Score | Interpretation |
|---|---|
| ≥ 9 | The SERPs of the parent-child pair are almost identical. |
| ≥ 6 and < 9 | The SERPs of the parent-child pair share a strong resemblance; but the SERPs are not identical. |
| ≥ 3 and < 6 | Although the resemblance between the SERPs of the parent-child pair isn’t immediately apparent, the SERPs share some points of resemblance. |
| < 3 | The SERPs of the parent-child pair don’t share any resemblance. Such pairs are excluded from the cluster tree. |
Important: Core updates in Google’s algorithms can significantly alter the layout of the SERP. So, the cluster tree may be out dated after a significant core update. You can still use it, but you may need to manually examine the resemblance of the SERP in case of doubt.
Natural Language Processing
Google’s algorithms does not – rather can not – process language the way you and I do.
So, Google uses natural language processing algorithms to transform natural language – the way humans use language – to numerical data called vectors.
The movie The Matrix illustrates this point brilliantly.

As a content publisher, you don’t need to know the nuts and bolts of how this works. A working-knowledge is more than sufficient. Primarily, you need to know about these aspects of natural language processing:
- Stop Words
(In future, if I find you need to know more aspects of NLP, I will add more of them here.)
Stop Words
Imagine you meet someone who has neither seen a dog nor an elephant. And you show that person a picture of a dog and an elephant and ask the person to spot the dog.
The person has no idea what a dog or an elephant looks like. So, he asks you for a clue.
You want to have a little fun with the person. So, you say – “Well, a dog has four legs.“
Do you think this clue will help the person? No. Both elephants and dogs have four legs. And because of that, you can’t use that as a feature to tell the difference between a dog and an elephant.
Instead, if you would have said, “Well, a dog is much smaller than an elephant,” the person would have instantly spotted the dog in the picture.
The same way, when Google looks at a query, it ignores words that commonly occur. The algorithm does this because common words do little to help it understand the query.
So, if you type the query ‘how much do mini english bulldogs cost‘, Google will ignore all the stop words. After removing the stop words, the query becomes ‘mini english bulldog cost.’
Readable provides a free tool to help you detect stop words in a query. You can access the tool here:
https://app.readable.com/text/stopwords/
After a while, you’ll get a knack for identifying stop words and you won’t have to rely on the tool much.
Now that the concepts are clear, let’s look at the guidelines.
Guidelines
The best way to understand these guidelines is through case studies. So, I’ll cover several cases of what to do with a parent-child pair in the cluster tree.
Case 1 – Parent-Child Pair Nearly Identical After Removing Stop Words
From the cluster tree, pick a parent-child pair. For example, are there miniature english bulldogs and is there a miniature english bulldog is a parent-child pair.
Next, strip the stop words from the two queries. In the parent query – are there miniature english bulldogs – the stop words are:
- are
- there
In the child query – is there a miniature english bulldog – the stop words are:
- is
- there
- a
The table below shows the parent-child queries after removing the stop words:
| Description | Parent | Child |
|---|---|---|
| Original Query | are there miniature english bulldogs | is there a miniature english bulldog |
| Query without Stop Words | miniature english bulldogs | miniature english bulldog |
When you compare the parent-child queries without the stop words, the two queries are nearly identical. In such cases, you need not create a subheading for the child query in the parent article.
Case 2: Parent-Child Pair Has 9+ Similarity Score
Consider the following parent-child pair:
are toy bulldogs extinct [4.0]
└── why are toy bulldogs extinct [10.0]
The similarity score for the parent-child pair is 10. This means that the child query strongly resembles the parent query. Therefore, you can target both queries with the same article.
But should you include the child query as a sub-heading in the parent article? Well, the answer depends on how different the format and the content of their answers are.
The answer for the parent query is a close-ended, yes-no-type answer. But the child query is an open-ended, tell-me-why-type answer.
Thus, the answer format and the answer content for the two queries are different. So, you can included the child query as a subheading under the parent article.
Let’s look at another parent-child pair:
do teacup english bulldogs exist [6.0]
└── do miniature english bulldogs exist [9.0]
In this case the similarity score suggests that the parent-child pair are nearly identical. Therefore, the same article can easily rank for both queries.
However, should the child query be a sub-heading in the parent article? To find that out, let’s see how different the answers are.
The answer to the parent query looks like a simple yes-no-type answer. And the answer to the child query looks like a yes-no-type answer as well. This shows us that the answer format is identical. Next, let’s look at the answer content.
The answer to parent query relates to teacup english bulldogs. And the answer to the child query relates to miniature english bulldogs. Now, ask yourself whether teacup english bulldogs and miniature english bulldogs are interchangeable.
If the two queries are interchangeable, then the answers for the parent query and the child query are identical in content and format. Therefore, you need not include the child query as a sub-heading under the parent query.
If the two queries are not interchangeable, then the answers for the parent query and the child query are identical in format but not in content. Therefore, you need to include the child query as a sub-heading under the parent query.
To check whether the two queries are interchangeable, you can rely on your knowledge about the subject and the content of the SERP.
I don’t know much about bulldogs. And I would like to know whether teacup english bulldogs and miniature english bulldogs are interchangeable. So, I’ll compare the results for both the queries to see how similar they are.
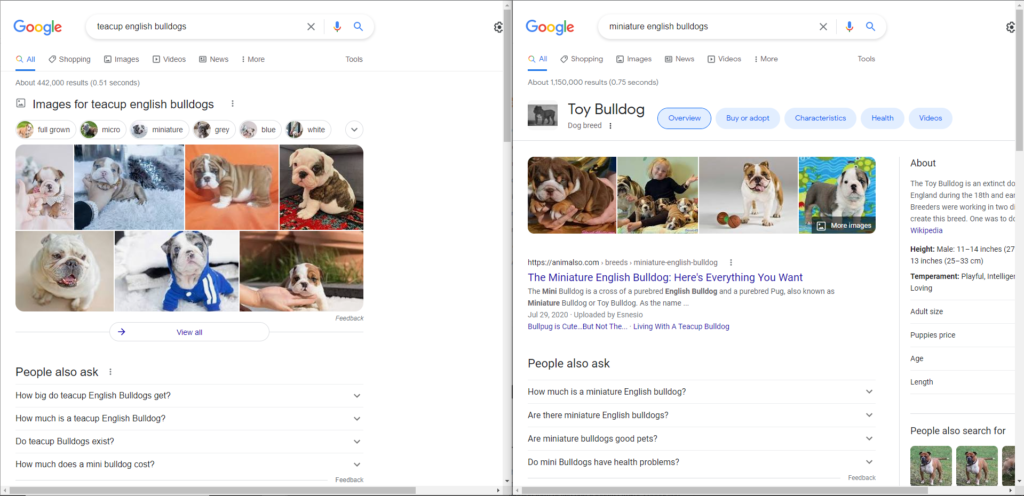
When looking at the SERP for the two queries side-by-side, I can see that the two queries are not interchangeable. Therefore, I can add the child query as a separate heading under its parent article.
Case 3: Parent-Child Pair has 6-8 Similarity Score
If the parent-child pair has a similarity score from 6 to 8, then the child shares a strong resemblance with the parent. But the child isn’t identical to the parent.
In such cases, you have four choices:
- Do nothing; ignore the child
- Include the child as a sub-heading in the parent article.
- Include the child as an interlinked article
- Include the child as a sub-heading and an interlinked article
Let’s go over these choices.
Do Nothing
If the parent and child queries are nearly identical after removing the stop words, you don’t need to do anything to entice Google’s algorithms to associate the child query with the parent query.
Include Child as a Sub-Heading
Exercise this option when the answer to the child query does not require elaboration.
If you can answer the child query to the complete satisfaction of the searcher in less than 200-300 words, then address the child query within the parent article.
In such cases, creating a separate article to address the child query does not make sense because 200-300 words won’t give search engines enough data to contextualize the information on the page.
Include Child as an Interlinked Article
If you feel that the child query doesn’t fit in with the rest of the sub-headings in the parent article, then you can include the child as an interlinked article.
In such cases, you can provide a link to an article addressing the child query in the related articles section at the end of the parent article.
Include Child as a Sub-Heading and as an Interlinked Article
This option suits situations where the child query requires elaboration.
The answer to the child query may depend on several considerations and giving a one-size-fits-all answer isn’t possible.
Also, you have enough to say about the query to write at least 1000 words.
If you find yourself in this position, create a sub-heading for the query in the parent article and write a short answer that addresses a typical scenario.
Then, list the factors that can influence the answer to deviate from the typical scenario.
After that inform the reader that you have written a separate article covering each of these factors and provide a contextual link to the article.
Also, make sure that you’re linking the article addressing the child query with the parent query.
For such articles, the goal is to win a featured snippet and a position on the first page of the SERP for the parent article and a position on the first page of the SERP for the child article.
Even if the child article does not rank, it’s fine. The child article will boost the relevance of the parent article through the internal link.
Case 4: Parent-Child Pair has 3-5 Similarity Score
When the similarity score between the parent and child is from 3 to 5, it means that the child shares enough resemblance with the parent to be a part of the same cluster.
But the child does not have enough in common with the parent to be featured prominently in the parent article.
So, what should you do in such cases?
Using a modified version of the fourth approach discussed in the previous case is the most appropriate course of action.
This means that you create a subheading for the child query in the parent article. But you provide no answers in the query.
Instead, you make a compelling appeal to the reader to read a separate article where you have addressed the child query in detail. Then provide a contextual link to the article.
Articles fitting this case, are meant to boost the authority of the parent article through internal link building.
Case 5: Identical Answer Format and Content
The similarity score is an incredibly helpful metric. But its not always spot on.
In some cases, you may feel that the same answer would fit both the parent and the child query.
In such cases, you can ignore the child query irrespective of what the similarity score says.
Case 6: Skipping Generations
Consider the following segment of a cluster tree.
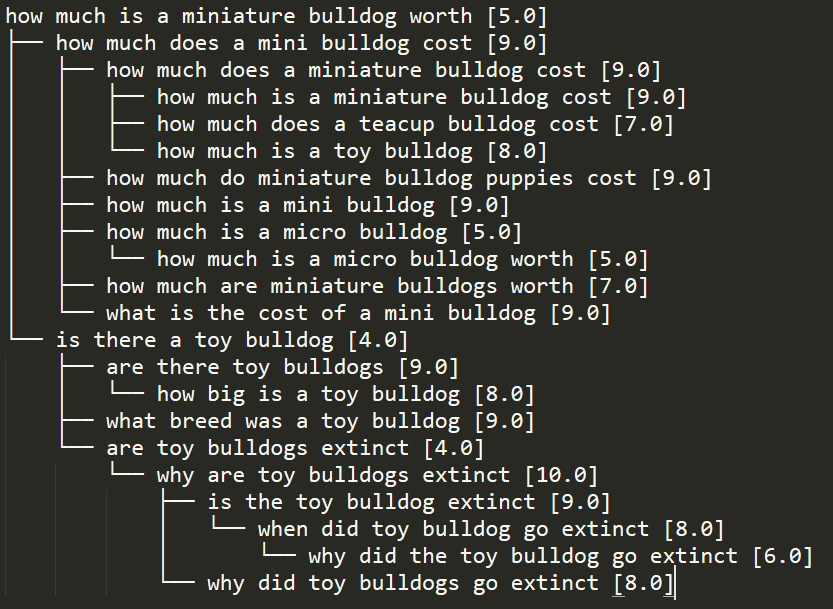
In this cluster segment, the parent query is how much is a miniature bulldog worth.
This parent query has two children. They are:
- how much does a mini bulldog cost
- is there a toy bulldog
Let’s examine the first child query.

In this cluster segment, look at the following parent-child pair:

For this parent-child pair, we can make these observations:
- The similarity score is 9
- After removing the stop words, the two queries are nearly identical
- The answer for the two queries are similar in format and content
For the above reasons, I don’t need to include the child query as a separate sub-heading. Nor do I have to write a separate article and link it to the parent article.
That’s all well and good. But what about the children of children?

Here’s what I recommend you do.
Since the child query is almost identical to the parent query, you can transfer the relationships from one generation to the next. Here’s what that looks like:
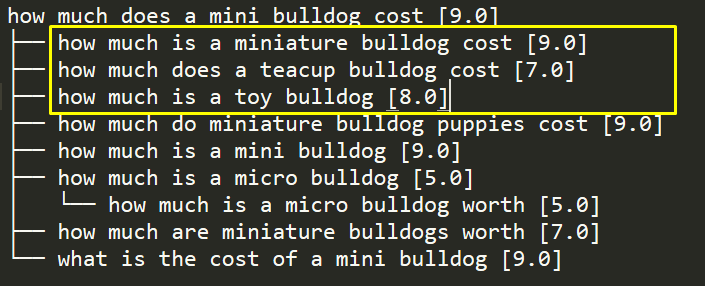
Now, you can choose to tackle the grand children in any of the four ways suggested in case 3.
But how do you handle grand children when the child is not identical to the parent? Let’s address that situation too.

For clarity, let’s list the parent, child, and grand child.
- Parent: how much does a mini bulldog cost
- Child: how much is a micro bulldog
- Grand Child: how much is a micro bulldog worth
In this case, the parent-child pair has a similarity score of 5. This suggests that you must create a separate – but interlinked – page for the parent and the child.
In such a situation, how would you handle the grand child?
Since the parent and the child queries aren’t identical, I cannot make the grand child skip a generation.
So, I can choose to address the grand child as a subheading in the child article or I can create a separate article for the grand child and link it to the child article.
But, in this case, even though the similarity score for the child-grandchild pair suggests you write a separate article for the grand child, I wouldn’t recommend it.
Here’s why:
Before you create separately interlinked articles for any query, make sure that you have at least 3 articles in the next level.
In this case, if I create another level below the child article for the grand child queries, I’ll have only one article at that level. So, it’s worth creating a separate level.
So, I’ll address the grand child query within the article addressing the child query.
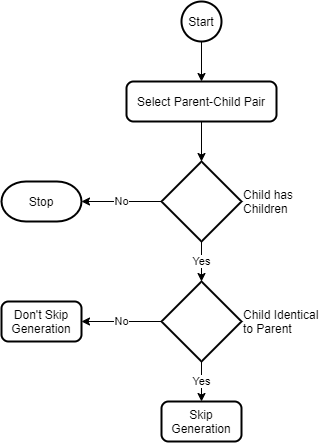
Decision Tree
Here’s the decision tree to help you decide how to handle the child query for a parent query.

The next decision tree will help you decide whether to skip a generation or not.